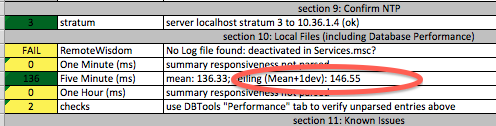
In revision 541, the basic capability to ask a DCNM service for the Nickname/WWPN mapping has been started. This has the potential to reuse the information entered into DCNM rather than re-entering manually, and avoid pulling zonefiles from each zone for parsing using a –nickname=file:// or –nickname=http:// method. As well, in situations where aliases are not used, we can collect the port labels or private aliases that DCNM may not share down to the switch.
This method is only initially defined, but requires a bit more work.
The same parser logic is used as was added for OnCommand in OnCommand Query and for BNA in BNA Query. Like the BNA and OnCommand work, the DCNM query simply reformats a query and sends it through the array of parsers to vote upon:
java -jar vict.jar --nickname=dcnmsql://user:pass@server:port/ --nicknameout=\VirtualWisdomData\DeviceNickname\nicknames.csv
Default user/pass should be accurate but need additional testing to confirm. Like the BNA parser, this method hits the underlying database directly, so it needs (firewalls/filters) direct access to the server, and is vulnerable to schema changes. Schema is based on 5.2 documentation.
In the meantime, cisco-shows2wwncsv.awk is also provided to build portlabel nicknames as import CSVs; this awk file needs two “show” commands on every switch. NOTE: every switch, not just every fabric, and it needs to see the output of “show flogi database” before it sees “show interface description”.